Network text analysis - Entities Clustering
by textanalyticsman
Introduction
Before getting into this post I want to say that for me programming is an art, it is a beautiful form to make real the things I can imagine, it is a way to release my dreams and my creativity and this is why I cannot work as a programmer; because this is beyond schedules and commercial pressures, this is part of the search.
The previous post was about using the software to fix miss-classified entities. Thus, so far we have covered the extraction and the classification of entities as was mentioned on the first post. So, this post is about the next problem to be solved after recognizing and classifying entities; the generation of cluster to recognize similar entities that are the same.
Clusters of entities
Choosing a distance function to compare entities
This process generates groups of entities according to their similarities to face cases where entities such as Doe, John Doe and John are the same. FreeLing has a co-referencing module to solve this problem. However, it works just for each document so this software generates a report based on how similar strings are through the whole corpus.
To create groups of similar entities, the software needs a distance function to measure how comparable entities are. Thus, this software uses the non-binary Jaccard distance, which works at tokens level. This is the definition of the Jaccard rate:
Let us say we have two strings S1 and S2. The Jaccard distance between them is calculated using the following formula.
\[Jd(S1,S2) = 1 - \frac {\mid S1 \cap S2 \mid}{\mid S1 \cup S2 \mid}\]The following example shows the meaning of this distance.
Let us say we have two strings
\[S1 = Pedro \\ S2 = Pedro\hspace{2mm}Rodriguez\]When we replace above strings on the Jaccard distance formula, we will have
\[Jd(S1,S2) = 1 - \frac {\mid \{Pedro\} \cap \{Pedro, \hspace{2mm}Rodriguez\} \mid}{\mid \{Pedro\} \cup \{Pedro, \hspace{2mm}Rodriguez\} \mid}\\\] \[Jd(S1,S2) = 1 - \frac {\mid \{Pedro\} \mid}{\mid \{Pedro, \hspace{2mm}Rodriguez\} \mid}\\\] \[Jd(S1,S2) = 1 - \frac{1}{2}\\\] \[Jd(S1,S2) = 0,5\]Thus, the Jaccard distance between the set of tokens \(\{Pedro\}\) and \(\{Pedro, Rodriguez\}\) is \(0.5\)
After choosing a distance function, the question is how to group these entities according to their Jaccard distance?
Clustering similar entities
Before presenting some details about the clustering algorithm used in this post, I would like to show with an example an intuitive notion of clustering sets of tokens.
Let us say we have the following list of entities.
- Raul
- Raul Castillo
- Castillo
- Raul Castillo Castillo
- Cesar
- Cesar Villacorta
- Villacorta
- Villacorta Guzman
- Arturo
- Arturo Lopez
- Lopez
First, in order to find groups of similar entities it is necessary to calculate a cost matrix represented by an edge list where each tuple has this information:
\[Tuple (i)= <Entity01, Entity02, Jaccard Distance, Flag visited>\]Where \(i=1..n\) and \(“n”\) is the number of entities
Each tuple is generated by the combination of two entities for example “Arturo” and “Arturo Lopez”. However, the total number of entities is equal to \(n * \frac{(n-1)}{2}\) because Jaccard distance is symmetric. Thus, in this case the edge list has \(11 * \frac{10}{2}\) tuples or 55 tuples. After calculating the Jaccard distance and after eliminating those tuples whose value is 1 (they are totally different); this table (an edges list) is generated.
| Entity01 | Entity02 | Jaccard distance | Flag visited |
|---|---|---|---|
| Raul | Raul Castillo | 0,50 | |
| Raul | Raul Castillo Castillo | 0,50 | |
| Raul Castillo | Castillo | 0,50 | |
| Raul Castillo | Raul Castillo Castillo | 0,50 | |
| Castillo | Raul Castillo Castillo | 0,50 | |
| Cesar Villacorta | Villacorta | 0,50 | |
| Cesar Villacorta | Villacorta Guzman | 0,67 | |
| Villacorta | Villacorta Guzman | 0,50 | |
| Arturo | Arturo Lopez | 0,50 | |
| Arturo Lopez | Lopez | 0,50 | |
| Cesar | Cesar Villacorta | 0,50 |
The previous table defines some paths between entities. For example, let us say we select the first entity called “Raul” its following entity is “Raul Castillo” and if we look for “Raul Castillo” its following entity is “Castillo” and if we continue with this procedure and marking those nodes that we visited, we will find disconnected graphs, which define some groups. In addition, the “Flag Visited” must be used to avoid repetition. In order to show this idea about clustering the previous table was loaded into Gephi to get a visual representation, which can be seen in the following picture.
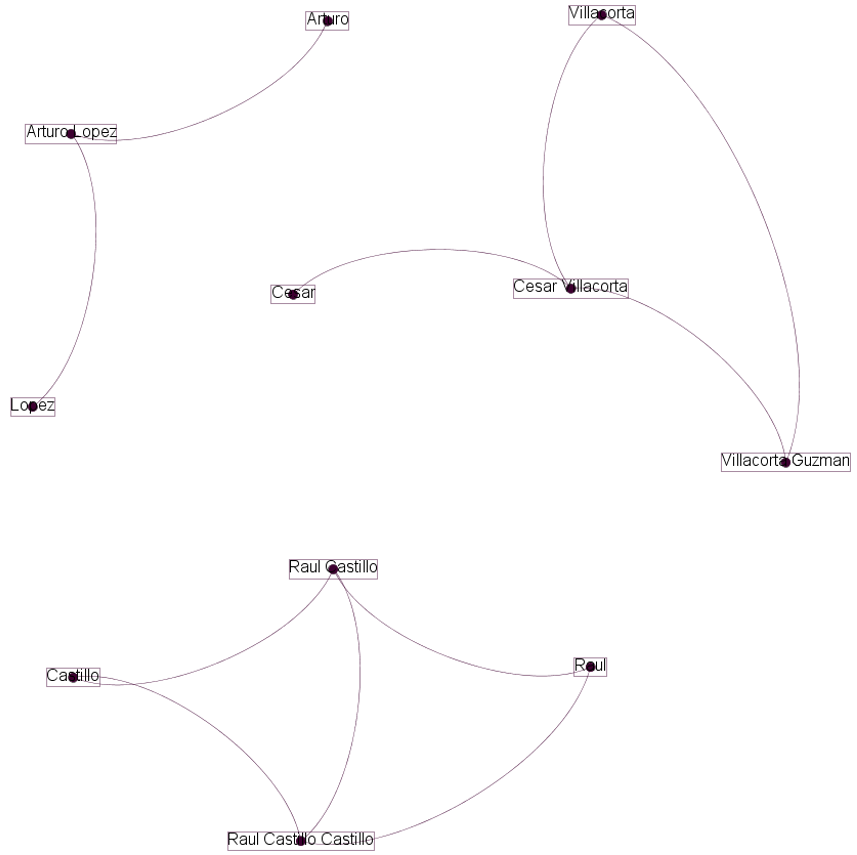 |
|---|
| Visualization of the edge list through Gephi |
The previous example shows an intuitive approach made on a group of entities. This example makes sense with Jaccard distance and paths defined in the edge list shows a reachability criteria. Thus, a suitable algorithm for this problem is the density-based spatial clustering of applications with noise (DBSCAN). DBSCAN receives two parameters ε, a threshold (in this case the Jaccard distance between two entities) used to find points that surround a given point “p” and minPts, which defines the minimum number of points that should be neighbours of “p”. DBSCAN can work with any kind of distance function. Following the main concepts related to this algorithm are presented.
Eps-neighbourhood, given a point “p” its Eps-neighbourhood is composed by all the points from a dataset D where the distance between p and each one of them is less than ε. This Eps-neighbourhood has a minimum size that is controlled by the parameter minPts. Since a cluster has core points and border points, this parameter should be smaller enough to include border points in the cluster.
- Directly density reachable, given two points “p” and “q”; “p” is density reachable from q when Eps-neighbourhood(q) is greater or equal than minPts and “p” belongs to Eps-neigh-bourhood(q).
- Density reachable, let us say there are two points “p” and “q”; p is density reachable from q if there is path (p-x1-x2…-xn-q) between them. In addition, each successor point within the path must be directly density-reachable from its predecessor. For example, “x1” is di-rectly density-reachable from “p”. This property is important because defines a path that is similar to the intuitive notion used to create groups shown in previous figure.
- Density-connected, given three points “p”, “q” and “o”; “p” and “q” are density connected when both are density reachable from “o”.
- Cluster, this is a partition from a given dataset “D” where for a point “p” (which belongs to the cluster) a point “q” will be included in the same cluster if “q” is density reachable from p. In addition, both points “p” and “q” must be also density connected.
- Noise, these are points from a given dataset “D” that do not belong to any cluster.
Generating clusters
After setting the theoretical basis about the algorithm used here, it is time to show how this software can be used to generate clusters of similar entities.
-
Click on Analyzer » Entities clustering.
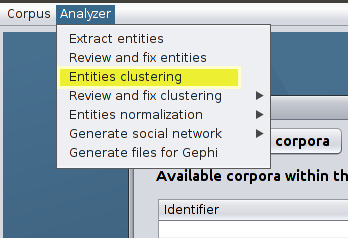
Option used to create entities’ clusters -
Click on Load available corpora and select the corpus you want to get entities’ clusters from.
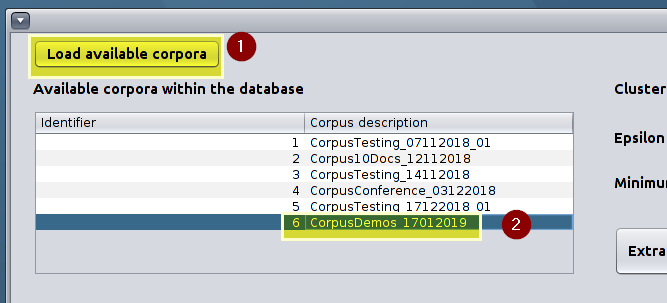
Choose the corpus you want to work -
Set the values for Epsilon ε and Minimum number of points minPts and click on “Extract cluster from selected corpus”.
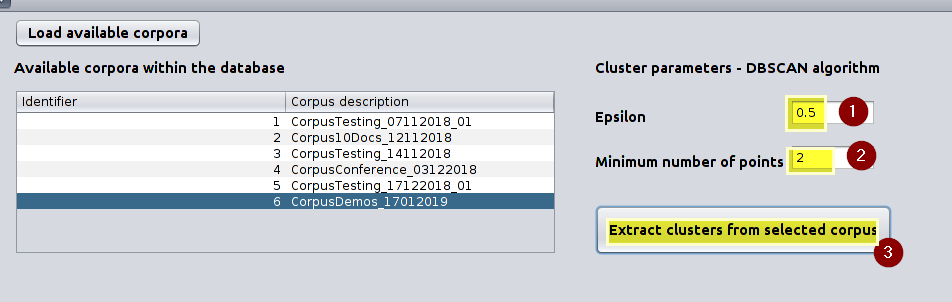
Setting the values for ε and minPts used to extract cluster through the DBSCAN algorithm -
Cluster are generated and the list of them are shown on the left as “List of clusters” if you click on any of them, you will see the details on the right panel called “Entities that belong to the selected cluster”.
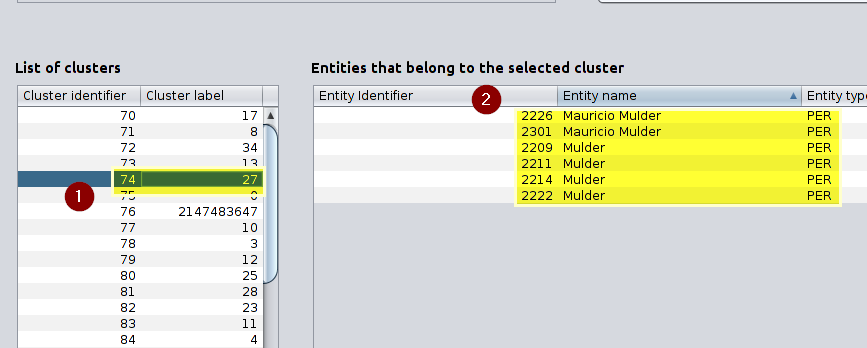
List of clusters and entities that belong to a selected cluster
Here you can see another example
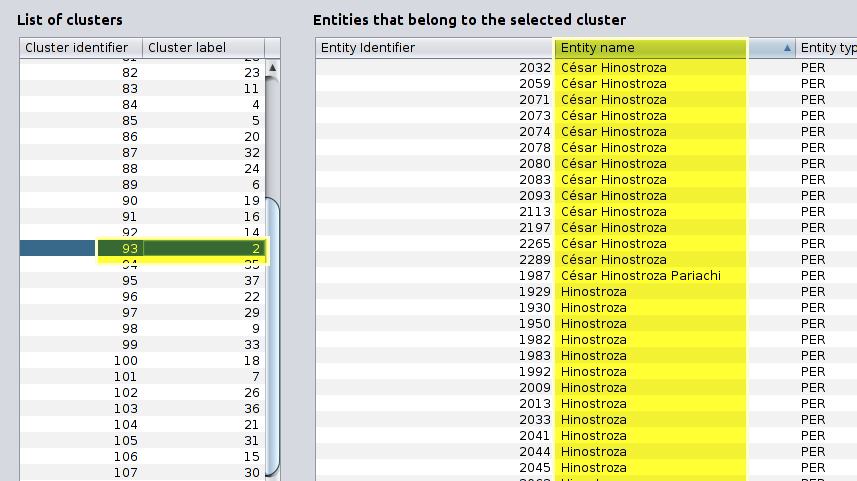 |
|---|
| List of clusters and entities that belong to a selected cluster |
And another
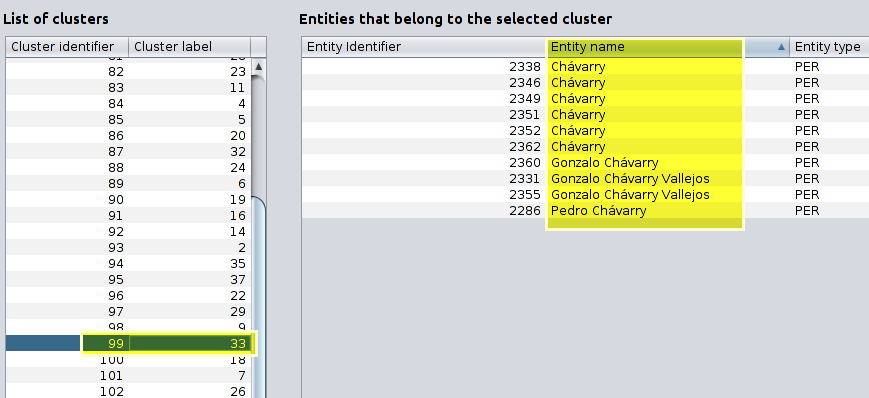 |
|---|
| List of clusters and entities that belong to a selected cluster |
Conclusion
This post has shown how to generate clusters of entities based on the Jaccard distance as a measure of similarity based on tokens and the algorithm called density-based spatial clustering of applications with noise (DBSCAN). So far we have managed to create clusters, but there are miss-clustered entities that should be fixed manually and even though this process is going to be hard, it is still much better than a pure manual process.
Subscribe via RSS