Network text analysis - Entities' Normalization
by textanalyticsman
Introduction
The previous post was about using the software to fix the clustering process. As the clustering process has been finished, it is time to generate normal entities to represent each cluster, this is a process, which selects the largest entity (based on the number of characters) to represent the entities that are part of the cluster. This process is just a complement for the clustering process.
The module presented in this section has three options that are described below.
Generate normalized entities
This module takes information about clusters that belongs to a corpus in order to discover the canonical entity that represents each cluster. For example, let us say a cluster is composed for these entities: “Pedro”, “Pedro Hernández Alvarez” and “Pedro Hernández”; this module selects the longest string, in this case the second one, to represent the whole cluster. Hence, this string is the normalized entity for this cluster. The following steps show how to use this option.
-
Click on Analyzer » Entities normalization » Generate normalized entities. This option will open a screen that will be explained in the next point.
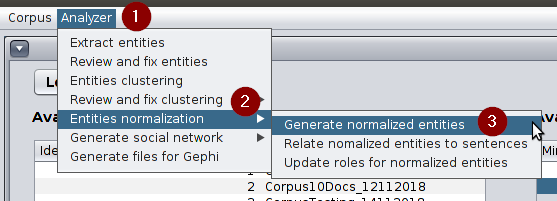
Option used to generate normalized or canonical entities for a corpus -
This screen is used to generate normalized entities. After clicking on “Load available corpora”, you should select the corpus and one of the available cluster(s) configuration (a combination of MinPts and Epsilon) to see the list of clusters that have been identified for this corpus. If you click on any of the available clusters you will see its members under the section Entities that belong to the selected cluster. What is more, if you click on “Extract normalized entities” they will appear below that button.
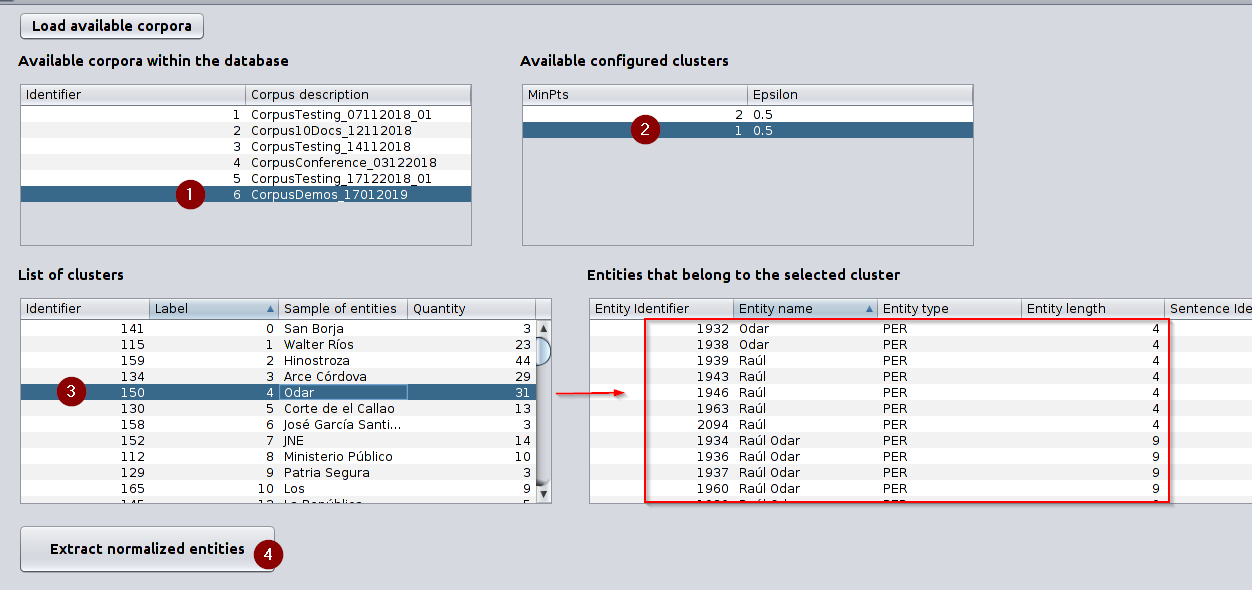
Screen used to extract canonical entities 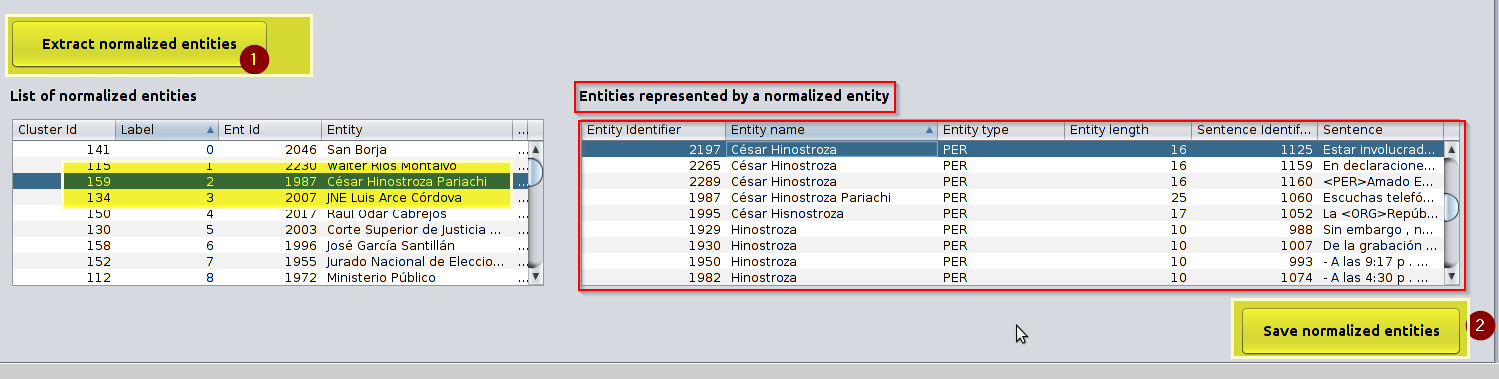
Canonical entities extracted after clicking on “Extract normalized entities”. -
Continuing with the previous screen, after clicking on “Save normalized entities” the set of canonical entities are saved on the database.
Relate normalized entities to sentences
This module executes a query to discover the relationship between normalized entities and sentences. These relationships are important for the process because the social network is created based on the co-ocurrence relationship between normalized entities that belong to the same sentence or paragraph. The following steps show how to use this option.
-
Click on Analyzer » Entities normalization » Relate normalized entities to sentences.
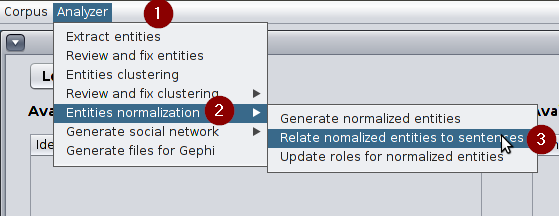
Option used to relate normalized entities and sentences -
Screen used to relate normalized entities and sentences After clicking on “Load available corpora”, you should select the corpus and the available cluster(s) configuration (a combination of MinPts and Epsilon) to see the list of normalized entities and then you should click on “Relate normalized entities with sentences”. After this, a panel with relationships is shown. You should click on “Save relationships” to save them on the database.
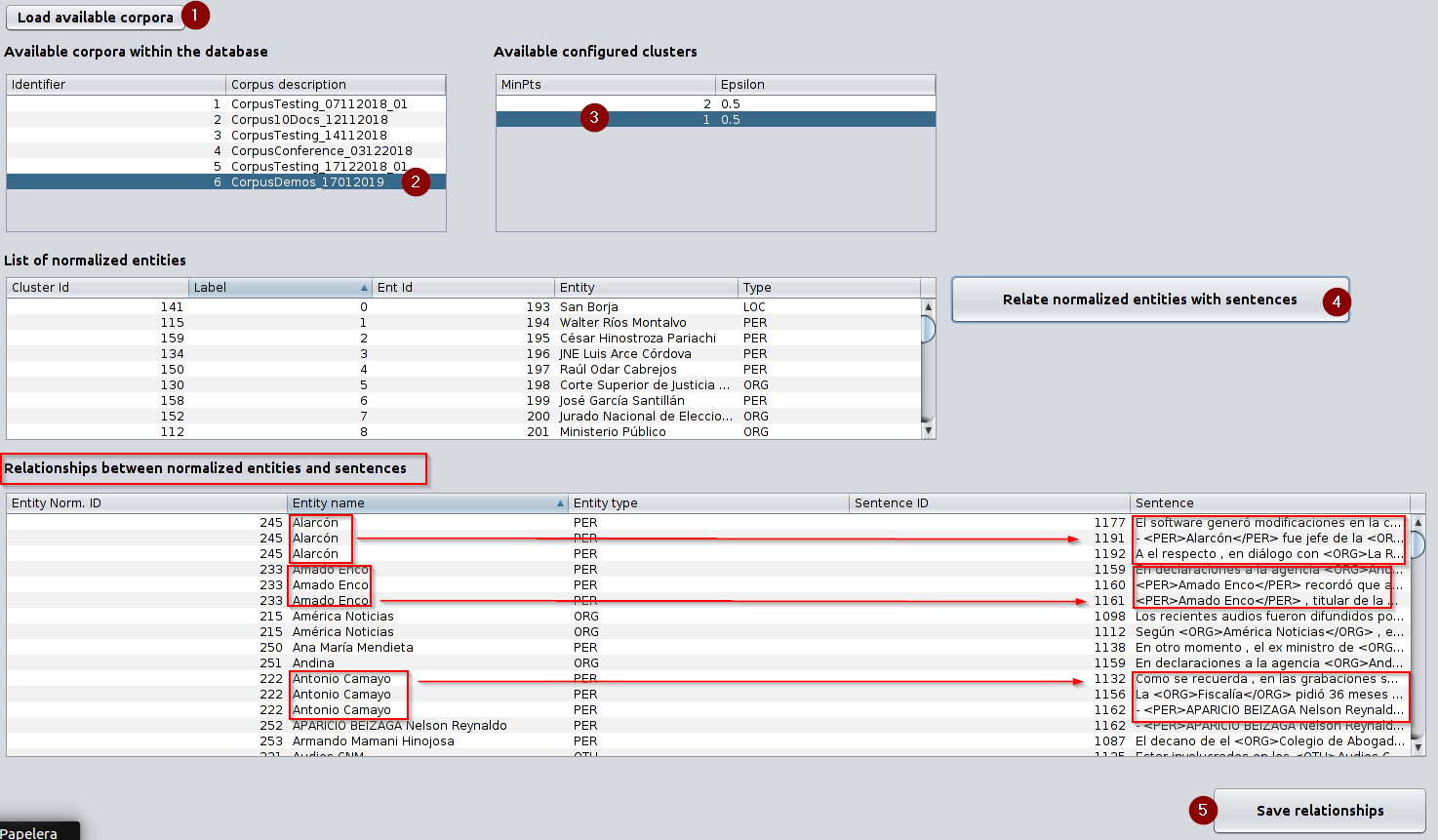
Screen used to generate relationships between canonical entities and sentences
Update roles for normalized entities
During the implementation, it was realized the original design lacks of a way to differentiate suspects victims, journalists, LEAs, etc. Thus, this module is developed to allow the user (human annotator) setting a role for each one of the normalized entities. Following the steps to do so are shown.
-
Click on Analyzer » Entities normalization » Update roles for normalized entities.
Option used to assign a role for each normalized entity -
Screen used to assign roles for normalized entities After clicking on “Load available corpora”, you should select the corpus and the available cluster(s) configuration (a combination of MinPts and Epsilon) to see the list of normalized entities and then you can use the combo box on the column Role to select the role for each entity. After filling all the roles you should click on “Update roles”
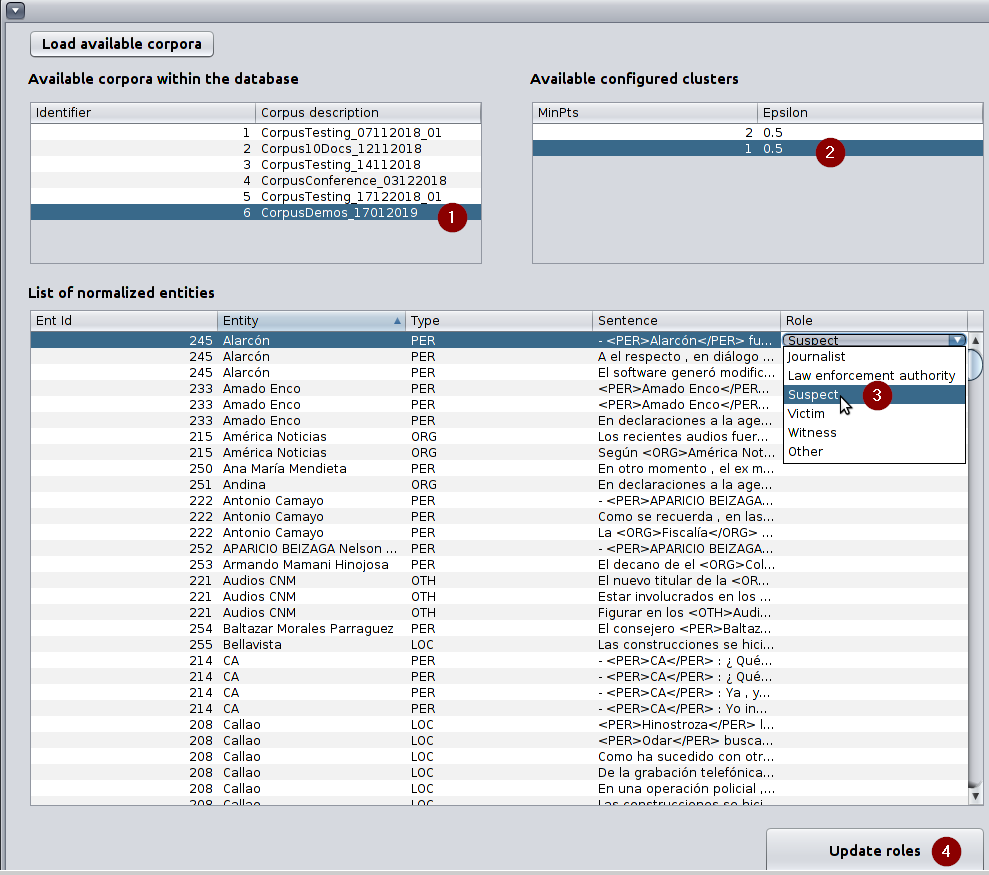
Option used to assign a role for each normalized entity
Conclusion
So far this software has been used to get the set of canonical entities (entity who represents a cluster) to relate them to the sentences extracted previously. This is important because is a way to normalize the names that are used to build social network of entities related to a criminal case. The process requires the user’s participation. However, it is still better than a pure manual process.
Subscribe via RSS